4.2. Static Word Embeddings
Contents
4.2. Static Word Embeddings#
In order to understand what word embeddings are, why do we need it and what are traditional word embeddings, please visit this page (link to the previous chapter).
In this section we will be describing various ways to find the vector representation of a word using the Static Word Embeddings approach.
Static Word embeddings and Contextual Word embeddings are slightly different.
Word embeddings provided by word2vec, Glove or fastText has a vocabulary (dictionary) of words. The elements of this vocabulary (or dictionary) are words and its corresponding word embeddings. Hence, given a word, its embeddings is always the same in whichever sentence it occurs. Here, the pre-trained word embeddings are static.
For example, consider the two sentences:
I will show you a valid point of reference and talk to the point.
Where have you placed the point.
However note that the context of a single contextual word is mostly preserved in this type of embedding. Let us explore further different types of static word embeddings.
Cosine Similarity#
It is the most widely used method to compare two vectors. It is a dot product between two vectors. We would find the cosine angle between the two vectors. For degree 0, cosine is 1 and it is less than 1 for any other angle.
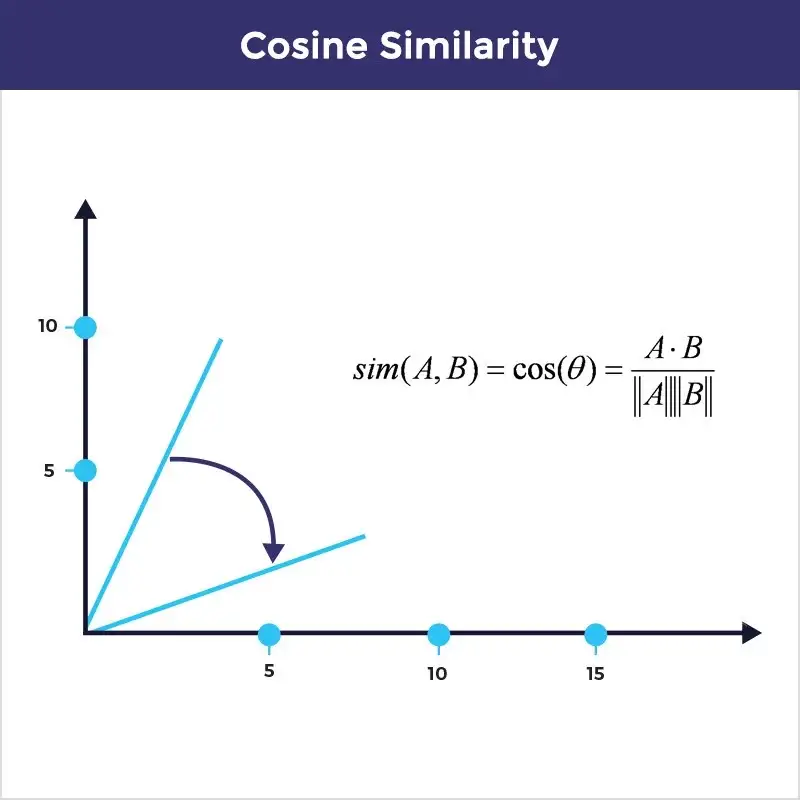
Let us compute cosine similarity between 2 vectors using sklearn’s cosine similarity module.
from sklearn.metrics.pairwise import cosine_similarity
A = [[1, 3]]
B = [[-2, 2]]
print("Cosine Similarity between A and B =", cosine_similarity(A, B))
Cosine Similarity between A and B = [[0.4472136]]